推薦系統(tǒng)中的矩陣分解與因子分解機(jī) 從協(xié)同過濾到高階特征交互
在推薦系統(tǒng)的演進(jìn)歷程中,協(xié)同過濾(Collaborative Filtering, CF)是奠定基礎(chǔ)的經(jīng)典方法。隨著數(shù)據(jù)規(guī)模的爆炸式增長和業(yè)務(wù)場(chǎng)景的日益復(fù)雜,傳統(tǒng)的協(xié)同過濾方法,如基于鄰域的方法,逐漸顯露出其局限性:難以處理大規(guī)模稀疏矩陣、無法有效利用豐富的輔助信息(如用戶屬性、物品特征、上下文等)。為了克服這些挑戰(zhàn),以矩陣分解(Matrix Factorization, MF)和因子分解機(jī)(Factorization Machines, FM)為代表的隱因子模型應(yīng)運(yùn)而生,它們不僅提升了推薦的精準(zhǔn)度,也為推薦系統(tǒng)開啟了從“用戶-物品”二維交互邁向高階特征組合分析的大門。
一、 矩陣分解:挖掘隱式偏好
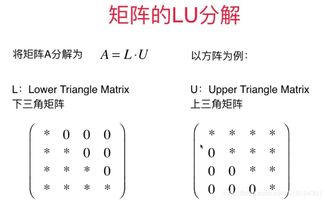
矩陣分解的核心思想是將龐大的“用戶-物品”評(píng)分矩陣(通常是高度稀疏的)分解為兩個(gè)低維稠密矩陣的乘積。具體而言,假設(shè)我們有m個(gè)用戶和n個(gè)物品,評(píng)分矩陣R (m×n)。矩陣分解旨在找到用戶隱因子矩陣P (m×k)和物品隱因子矩陣Q (n×k),使得它們的乘積近似于原始評(píng)分矩陣:R ≈ P * Q^T。
其中,k是隱因子的維度,通常遠(yuǎn)小于m和n。用戶i對(duì)物品j的預(yù)測(cè)評(píng)分可以表示為:r?{ij} = pi · qj^T,這里pi是P中代表用戶i的k維隱向量,q_j是Q中代表物品j的k維隱向量。這些隱因子是模型自動(dòng)學(xué)習(xí)得到的,它們可以解釋為一些抽象的、可度量的“特征”,例如電影推薦中的“浪漫程度”、“動(dòng)作成分”,或者音樂推薦中的“節(jié)奏感”、“流派偏向”。
矩陣分解的優(yōu)勢(shì)在于:
- 解決稀疏性:通過將數(shù)據(jù)映射到低維空間,有效緩解了數(shù)據(jù)稀疏問題。
- 可擴(kuò)展性:模型參數(shù)數(shù)量為(m+n)k,遠(yuǎn)小于原始評(píng)分矩陣的mn,便于處理大規(guī)模數(shù)據(jù)。
- 隱語義挖掘:能夠自動(dòng)發(fā)現(xiàn)用戶和物品背后潛在的、未觀測(cè)到的關(guān)聯(lián)。
經(jīng)典的矩陣分解模型(如FunkSVD)通過最小化預(yù)測(cè)評(píng)分與實(shí)際評(píng)分的均方誤差來進(jìn)行優(yōu)化。在此基礎(chǔ)上,加入偏置項(xiàng)(用戶偏置、物品偏置和全局平均分)的偏置矩陣分解(Biased MF)以及考慮時(shí)間動(dòng)態(tài)的時(shí)間敏感矩陣分解(TimeSVD++)等變體,進(jìn)一步提升了模型的表達(dá)能力。
標(biāo)準(zhǔn)矩陣分解本質(zhì)上仍是一個(gè)只利用“用戶ID-物品ID”交互的模型。當(dāng)面對(duì)豐富的特征信息(如用戶 demographics、物品標(biāo)簽、瀏覽時(shí)間等)時(shí),其建模能力就顯得捉襟見肘。
二、 因子分解機(jī):邁向高階特征工程
因子分解機(jī)正是為了突破這一限制而設(shè)計(jì)的通用預(yù)測(cè)器。它不僅可以模擬矩陣分解(將用戶ID和物品ID視為兩個(gè)特征),更可以無縫地融入任意數(shù)量的實(shí)值特征,并對(duì)所有特征之間的交互進(jìn)行建模。
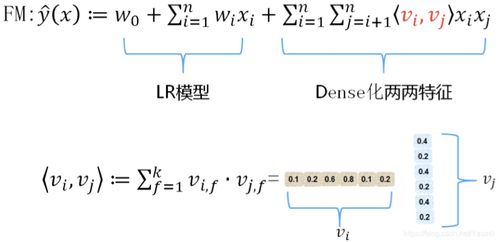
FM模型的預(yù)測(cè)公式如下:
?(x) = w0 + Σ{i=1}^{n} wi xi + Σ{i=1}^{n} Σ{j=i+1}^{n} ?vi, vj? xi xj
其中:
- w_0是全局偏置。
- w_i建模特征i的一階重要性(線性部分)。
- 核心部分是二階交互項(xiàng):?vi, vj?是特征i和特征j的隱向量vi和vj的點(diǎn)積,用于建模兩個(gè)特征之間的交互效應(yīng)。每個(gè)特征xi都關(guān)聯(lián)一個(gè)k維隱向量vi。
FM的巧妙之處在于,它通過對(duì)交互參數(shù)進(jìn)行矩陣分解(即假設(shè)交互參數(shù)矩陣W是低秩的),將交互參數(shù)的個(gè)數(shù)從O(n2)大幅降至O(n*k),這使得FM即使在極度稀疏的數(shù)據(jù)下也能有效估計(jì)特征交互。
FM與MF的關(guān)系:如果將特征集僅設(shè)定為用戶ID和物品ID的one-hot編碼,那么FM的二階交互部分就完全退化成了矩陣分解模型。因此,MF可以被視為FM在特定特征配置下的一個(gè)特例。FM是MF在特征維度上的泛化和擴(kuò)展。
三、 矩陣分解系統(tǒng)與FM的實(shí)踐與應(yīng)用
在現(xiàn)代推薦系統(tǒng)架構(gòu)中,矩陣分解和FM通常作為核心的召回(Recall)或排序(Ranking)模型嵌入其中。
- 作為召回層:學(xué)習(xí)到的用戶隱向量和物品隱向量可以用于高效的向量相似度計(jì)算(如余弦相似度)。通過近似最近鄰搜索(ANN)技術(shù),系統(tǒng)可以快速從海量物品庫中檢索出與用戶興趣最相關(guān)的數(shù)百個(gè)候選物品,送入后續(xù)的排序階段。
- 作為排序?qū)?/strong>:FM因其強(qiáng)大的特征組合能力,常被用作精細(xì)化的排序模型。它可以融合用戶歷史行為、物品屬性、上下文信息(時(shí)間、地點(diǎn)、設(shè)備)、以及從其他渠道(如圖像、文本)提取的深度特征,對(duì)所有特征進(jìn)行二階(甚至通過擴(kuò)展實(shí)現(xiàn)更高階)的交互建模,從而更精準(zhǔn)地預(yù)測(cè)用戶對(duì)某個(gè)候選物品的點(diǎn)擊率(CTR)、轉(zhuǎn)化率(CVR)或評(píng)分。
- 系統(tǒng)實(shí)現(xiàn):高效的實(shí)現(xiàn)對(duì)于工業(yè)級(jí)應(yīng)用至關(guān)重要。FM模型的計(jì)算可以通過公式改寫進(jìn)行優(yōu)化,使其計(jì)算復(fù)雜度線性于特征數(shù)量和非零特征數(shù)量。如今,F(xiàn)M及其衍生模型(如FFM, DeepFM)已被集成進(jìn)諸多機(jī)器學(xué)習(xí)平臺(tái)(如LibFM, xLearn, TensorFlow, PyTorch)。在分布式環(huán)境下,可以使用Spark MLlib或參數(shù)服務(wù)器架構(gòu)進(jìn)行大規(guī)模訓(xùn)練。
四、 與展望
從矩陣分解到因子分解機(jī),代表了推薦算法從單純的“協(xié)同”走向“特征融合”與“深度理解”的重要路徑。MF以其簡潔優(yōu)雅的方式揭示了用戶與物品間的潛在結(jié)構(gòu),而FM則提供了一個(gè)靈活的框架,將推薦問題轉(zhuǎn)化為一個(gè)能夠消化多源異構(gòu)數(shù)據(jù)的標(biāo)準(zhǔn)預(yù)測(cè)任務(wù)。
盡管當(dāng)前深度學(xué)習(xí)模型(如神經(jīng)協(xié)同過濾NCF、 Wide & Deep、DeepFM)在推薦領(lǐng)域大放異彩,但MF和FM所蘊(yùn)含的思想——低維嵌入、隱語義建模、稀疏特征下的高效交互——仍然是這些復(fù)雜模型的基石。理解矩陣分解和因子分解機(jī),不僅是掌握經(jīng)典推薦技術(shù)的鑰匙,更是通往構(gòu)建更智能、更個(gè)性化推薦系統(tǒng)道路上的堅(jiān)實(shí)一步。未來的發(fā)展,將繼續(xù)圍繞如何更高效、更智能地融合與利用多模態(tài)、動(dòng)態(tài)演化的數(shù)據(jù),而MF與FM的精神內(nèi)核,將持續(xù)在其中閃耀光芒。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.hibernate.org.cn/product/282.html
更新時(shí)間:2026-04-13 11:08:19